

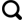
0 引言
页岩储层组分复杂、非均质性强,传统的多元线性回归、经验公式及岩石体积物理模型等方法,往往难以充分捕捉储层参数与测井曲线之间复杂的高维非线性关系,导致预测精度受限。为探索以LightGBM为代表的机器学习方法在深层页岩储层分级评价中的适用性,本文以四川盆地渝西地区上奥陶统五峰组—下志留统龙马溪组一段1亚段(简称龙一1亚段)深层页岩为研究对象。首先,利用LightGBM算法分别构建基于回归和分类方案的深层页岩储层类型识别模型(模型训练过程中使用贝叶斯优化算法进行超参数调优),对比分析两者的识别性能,优选最佳方案;其次,基于SHAP(SHapley Additive exPlanations)算法分析测井曲线对不同类型页岩储层识别的重要性;最后,将最优储层类型识别模型应用于研究区目的层段深层页岩储层分级评价,以期为深层页岩储层甜点段优选提供新思路。
1 方法原理
1.1 LightGBM算法
式中:ŷi 表示第i个样本的预测值;fk 表示第k棵决策树;F表示由决策树构成的函数空间。
LightGBM的目标函数(Obj)包含2部分:训练损失和决策树结构复杂度。其中,决策树结构复杂度作为惩罚项引入,能有效降低过拟合风险。Obj可表示为[式(2) ]:
式中:l表示训练损失,即第i个样本预测值(ŷi )和真实值(yi )之间的误差;Ω(fk )表示第k棵决策树的结构复杂度;T表示叶子节点数量;||w||2表示所有叶子节点权重向量的平方和;γ和λ为超参数。
为提升大规模数据处理效率和减少内存占用,同时不明显损失精度,LightGBM针对传统梯度提升算法XGBoost[22]进行了多项优化,最核心的是直方图算法和Leaf-wise树生长策略。
1.2 贝叶斯优化
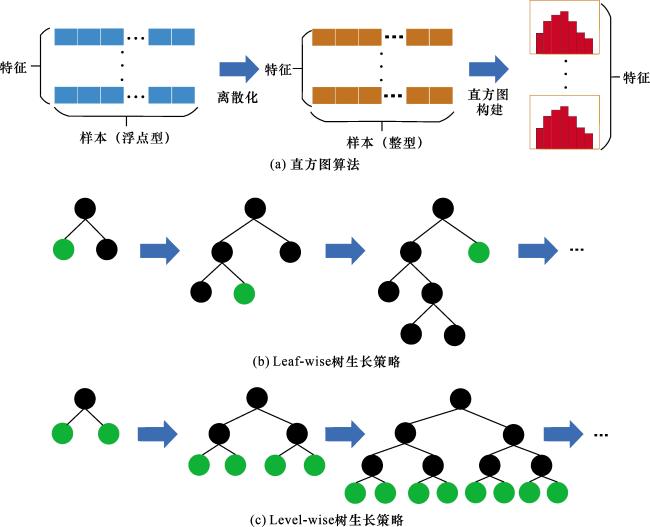
在机器学习模型构建中,超参数优化是提升模型性能的关键环节。LightGBM拥有大量复杂且相互影响的超参数,这些超参数对模型的预测性能具有较大的影响,而手动或传统搜索方法效率较低。贝叶斯优化通过建立概率模型智能地利用历史评估结果,以最少的实验次数(n_trials)自动找到高性能的参数组合,极大地节省了调查时间和计算成本。贝叶斯优化方法由Jonas Mockus在IFIP会议首次系统提出[23],其核心思想是通过建立目标函数的概率代理模型,并利用采集函数指导序贯采样,达到对高维超参数空间的高效调优(图2)。贝叶斯优化的主要流程为:①在超参数空间中通过随机抽样或拉丁超立方体等方法获取初始观测点;②基于初始观测点构建目标函数f(x)的概率代理模型(如高斯过程、高斯混合模型等),获得f(x)的分布估计f*(x);③通过最大化采集函数(如概率增量、期望增量和置信度上界等)确定新观测点,并依次更新代理模型、f*(x)和采集函数。以上过程迭代进行,直至达到预设的评估次数或收敛阈值,最终输出全局最优解。相比网格搜索和随机搜索,贝叶斯优化能以相对较少的时间和较低的计算成本,近似找到复杂目标函数的最优解,显著提升了超参数优化效率[24]。
1.3 SHAP算法
为分析LightGBM模型的决策机制,本文研究采用SHAP算法进行特征归因[25]。该算法的核心思想基于合作博弈论中的Shapley值理论,将机器学习模型的预测视为一个“合作博弈”:每个特征是一个“玩家”,模型的预测结果是“游戏的总收益”。SHAP值的目标是公平分配该“总收益”给每个特征,以反映其对最终预测的真实贡献。给定模型f(x),特征i的SHAP值(φi )定义为该特征在所有特征子集下的边际贡献期望[式(3) ]:
式中:F表示所有特征的集合,数量为M;S表示不含特征i的子集;fx (S)表示模型在特征子集S上的预测值; 表示子集S的特征组合情况占比。
SHAP的核心优势在于其模型无关性、全局/局部解释的统一性以及方向一致性:它支持神经网络、随机森林、支持向量机等多种机器学习模型,使其成为通用解释工具;在解释机制上,所有特征的SHAP值之和等于模型对单个样本的预测值与基线预测值(如平均值)的差异,从而统一了局部解释,并且通过聚合单一样本的SHAP值即可实现全局特征重要性的解释;此外,SHAP值的符号具有方向一致性,正值始终表示增加预测值,负值则表示减小预测值。
2 地质背景与数据准备
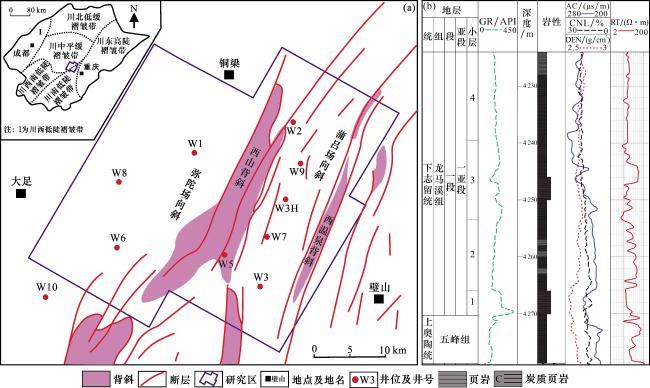
2.1 地质背景
2.2 数据收集与探索
本论文数据源自渝西地区10口页岩气评价井,井位分布见图3(a)。测井资料包括自然伽马(GR)、声波时差(AC)、密度(DEN)、补偿中子(CNL)及电阻率(RT)。实验测试数据共计571组,包含4个页岩储层参数:总有机碳(TOC)含量、孔隙度、含气量(现场解吸法测得损失气、解吸气及残余气之和)以及脆性指数(石英、长石和碳酸盐矿物之和与总矿物含量之比)。鉴于RT曲线数值跨度大(5.41~239.83 Ω·m),预先对其进行常用对数处理,后续数据分析及机器学习建模均使用LgRT。
由于页岩储层成分复杂、非均质性强,储层参数与测井曲线间常呈非线性关系。因此,采用斯皮尔曼相关系数分析TOC含量、孔隙度、含气量及脆性指数4个参数与测井数据的相关性(图4)。斯皮尔曼相关性分析可基于有限实验数据,在保留信息的同时完成关联筛查,不仅能为页岩储层分级提供参数优先级,还能规避多重共线性,探索变量单调关联趋势,为研究假设提供初步参考证据。结果显示:与TOC含量、含气量及脆性指数相关性最强的均为DEN曲线,相关系数分别为-0.75、-0.75和-0.66。其次为CNL曲线,相关系数分别为-0.51、-0.56及-0.62。孔隙度与AC呈最强正相关(0.67),与DEN呈最强负相关(-0.53)。尽管部分测井曲线与储层参数的相关性不强(例如AC与脆性指数的相关系数为-0.05,LgRT与TOC含量的相关系数为0.08),但这些曲线仍包含一定的储层信息,对参数预测有所贡献。同时,测井曲线仅有5条,即使减少部分曲线,计算开销也不会显著降低。因此,后文建模将使用全部5条测井曲线。
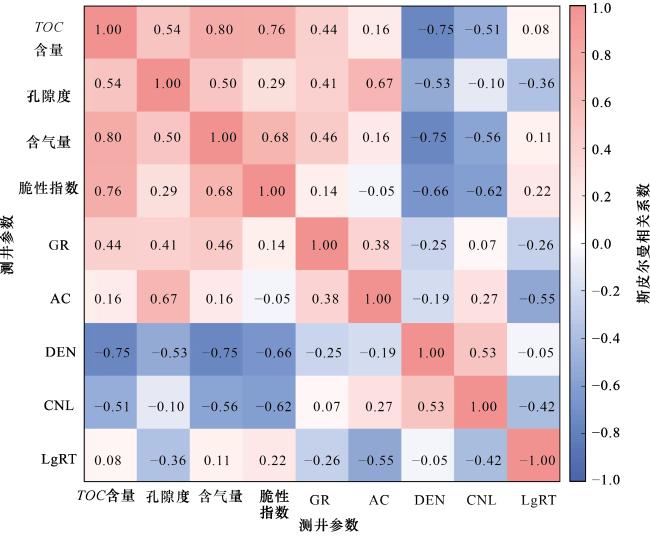
表1 川南深层页岩储层分级标准Table 1 Grading standard of deep shale reservoirs in southern Sichuan Basin |
| 页岩储层参数 | 单参数分级标准 | 单参数权重系数 | 不同级别储层赋值 | 综合分级标准 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Ⅰ类储层 | Ⅱ类储层 | Ⅲ类储层 | Ⅰ类储层 | Ⅱ类储层 | Ⅲ类储层 | Ⅰ类储层 | Ⅱ类储层 | Ⅲ类储层 | ||
| TOC含量/% | ≥3 | [2,3) | <2 | 0.3 | 1 | 0.7 | 0.4 | ≥0.85 | [0.6,0.85) | <0.6 |
| 孔隙度/% | ≥5 | [3,5) | <3 | 0.2 | ||||||
| 含气量/(cm3/g) | ≥3 | [2,3) | <2 | 0.3 | ||||||
| 脆性指数/% | ≥55 | [35,55) | <35 | 0.2 | ||||||
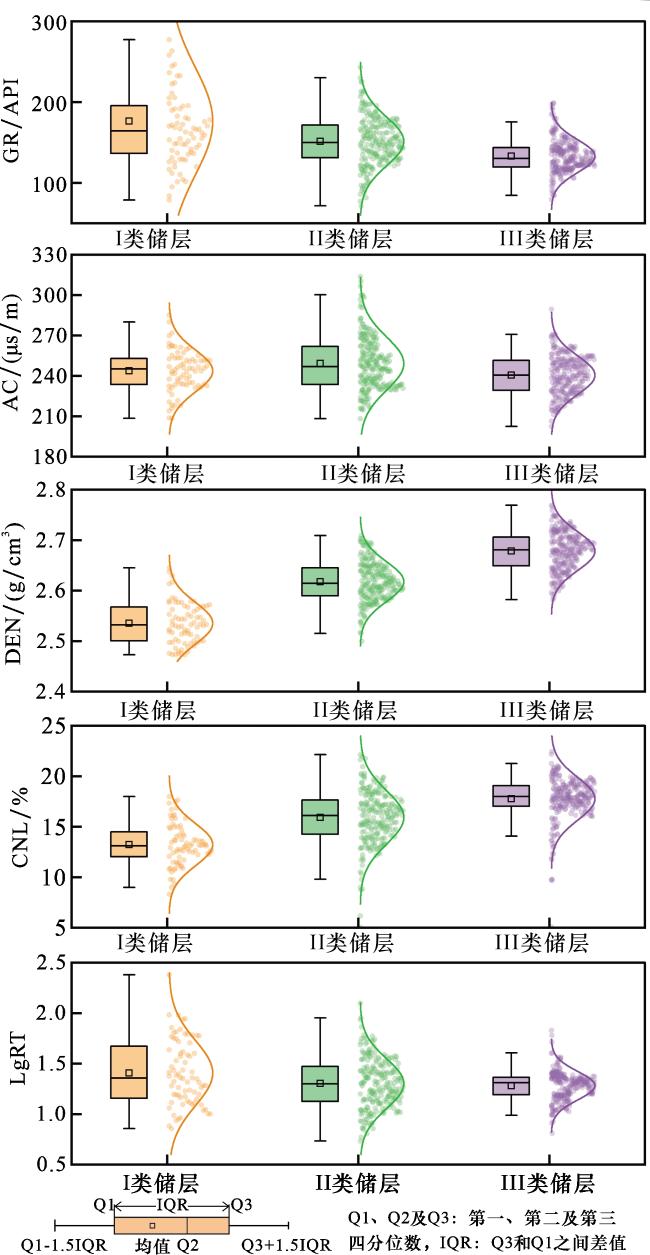
不同类型储层的测井曲线箱线图显示(图5),对于GR曲线,I类储层表现出较大的分布离散性,而II类和III类储层分布相对集中,且其中位数和平均值从I类到III类呈减小趋势。对于AC曲线,II类储层分布更为离散,其中位数和平均值也高于I类和III类储层,但3类储层的AC数据分布范围重合度较高。DEN和CNL曲线在3类储层间的分布差异较为明显,中位数和平均值均表现出从I类到III类依次增大的规律。LgRT曲线在3类储层间的分布范围重合度较高,仅I类储层的平均值和中位数略高。综上所述,DEN、CNL及GR曲线对储层类型具有相对较强的区分能力,而LgRT曲线的区分能力则较弱。
2.3 数据预处理及评价指标
为消除数据尺度和量纲差异,加快模型收敛,对5条测井曲线(GR、AC、DEN、CNL、LgRT)和4个储层参数(TOC含量、孔隙度、含气量、脆性指数)进行了Z-score标准化(式4 )[29]。标准化后数据服从均值为0、标准差为1的正态分布。标准化前,样本数据按8∶2比例随机划分为训练集(用于建模)和测试集(用于评估模型泛化能力)。
式中:x*表示标准化后数据;x表示原始数据;μ表示原始数据的均值;σ表示原始数据的标准偏差。
表2 回归和分类模型的评价指标Table 2 Evaluation indicators for regression and classification models |
| 评价指标 | 计算公式 | |
|---|---|---|
| 回归 模型 | RMSE | |
| R 2 | ||
| 分类 模型 | P | |
| R | ||
| Weighted-P | ||
| Weighted-R | ||
|
3 页岩储层类型识别模型
3.1 超参数调优
为提高LightGBM模型的精度和泛化能力,需优化关键超参数:决策树数量(n_estimators)、最大树深度(max_depth)、学习率(learning_rate)、叶子节点数(num_leaves)和叶子节点最小样本数(min_child_samples)。增加n_estimators能提升性能但增加模型复杂度及过拟合风险。max_depth和num_leaves共同控制树结构,增大能捕捉更复杂特征但也易过拟合,通常num_leaves≤2^(max_depth)。learning_rate控制单棵树贡献权重,较小值使模型更保守但可能更精确。min_child_samples限制叶子最小样本数以防止过深树,减小该值会增加复杂度及过拟合风险。
表3 基于LightGBM算法的4个页岩储层参数回归预测模型超参数搜索范围及最优值Table 3 Range and optimal values of hyperparameters for four shale reservoir parameter regression prediction models based on LightGBM algorithm |
表4 基于LightGBM、RF和SVM的页岩储层类型识别模型超参数搜索范围及最优值Table 4 Range and optimal values of hyperparameters for shale reservoir type identification model based on LightGBM, RF, and SVM |
| 算法类型 | 超参数 | 搜索范围 | 步长 | 最优值 |
|---|---|---|---|---|
| LightGBM | n_estimators | [50,200] | 1 | 90 |
| max_depth | [3,8] | 1 | 3 | |
| learning_rate | [0.001,0.1] | 对数空间均匀采样 | 0.087 | |
| num_leaves | [5,31] | 1 | 7 | |
| min_child_samples | [5,20] | 1 | 9 | |
| reg_alpha | [0.4,0.7] | 线性空间均匀采样 | 0.444 | |
| reg_lambda | [0.4,0.7] | 线性空间均匀采样 | 0.401 | |
| RF | n_estimators | [50,200] | 1 | 63 |
| max_depth | [3,8] | 1 | 8 | |
| min_samples_split | [5,15] | 1 | 7 | |
| min_samples_leaf | [5,15] | 1 | 15 | |
| SVM | C | [0.01,5] | 对数空间均匀采样 | 0.150 |
| gmma | [0.01,5] | 对数空间均匀采样 | 0.083 |
3.2 模型性能评价
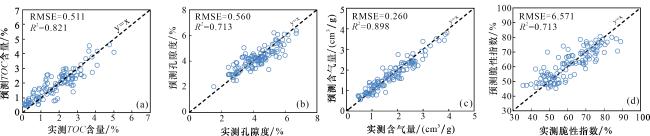
3.2.1 回归方案
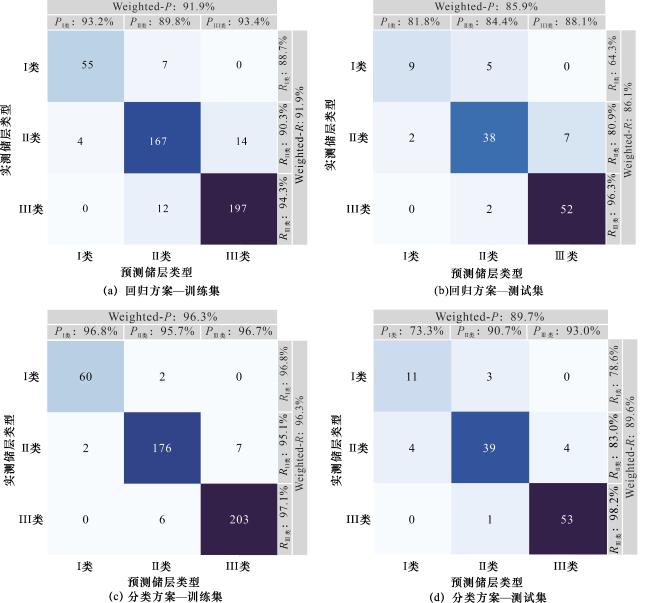
基于上述回归预测结果结合分级标准,进行页岩储层类型识别。分类识别混淆矩阵显示[图7(a),图7(b)],训练集上I、II、III类储层识别的P分别为93.2%、89.8%、93.4%(Weighted-P为91.9%),R分别为88.7%、90.3%、94.3%(Weighted-R为91.9%)。测试集上I、II、III类储层识别的P分别为81.8%、84.4%、88.1%(Weighted-P为85.9%),R分别为64.3%、80.9%、96.3%(Weighted-R为86.1%)。虽然测试集的Weighted-P和Weighted-R这2个指标显示该方案对不同类型储层识别的泛化能力整体较强,但I类储层识别的R值较低,仅为64.3%,P值也是3类储层当中最低的,表明该方案对I类储层的识别性能可能存在较大的局限性。
3.2.2 分类方案
综上,通过比较单一储层类型识别的P、R及加权综合指标,分类方案的识别性能显著优于回归方案,这主要是因为回归方案中4个储层参数的回归预测误差会产生级联累积效应。此外,回归方案需构建4个独立回归模型,而分类方案只需单一分类模型即可实现页岩储层类型识别,在模型复杂度与计算效率上具有显著优势。相较于回归方案,分类方案具有更好的识别性能、更高的计算效率和更低的模型复杂度。
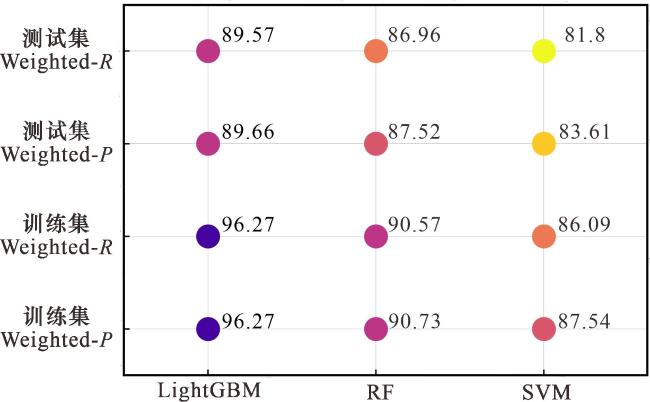
本文同时采用基于分类方案的RF及SVM算法对页岩储层类型进行识别,并与LightGBM算法的识别性能进行对比。RF与SVM算法已被广泛应用于油气地质领域,相关算法原理不再赘述[32-34]。分析结果显示(图8),对于RF算法,训练集Weighted-P、Weighted-R分别为90.73%、90.57%,测试集Weighted-P、Weighted-R分别为87.52%、86.96%;对于SVM算法,训练集Weighted-P、Weighted-R分别为87.54%、86.09%,测试集Weighted-P、Weighted-R分别为83.61%、81.8%;整体上看,LightGBM算法对于页岩储层类型的识别性能略优于RF,而SVM的识别性能较前两者有相对较大差距。由于LightGBM和RF均为基于CART决策树的集成学习算法,因此,两者对页岩储层类型的识别性能十分接近。同时,LightGBM采用梯度提升框架,通过序列化构建弱学习器,每棵新决策树都专注于修正前序模型的残差,能够更有效地提升模型精度。而RF通过并行构建独立决策树,然后投票集成,每棵决策树的构建只使用特征子集,增加了多样性但可能丢失重要特征的完整信息。因此,LightGBM对页岩储层类型的识别性能略优于RF。SVM算法性能相对较差的主要原因在于其调参复杂性与数据规模的矛盾,有限的456个训练集样本难以支撑非线性核函数(rbf核)所需的高维复杂边界,而三分类问题更需为多个二分类器分别寻找正则化参数C和核参数gamma的完美组合。这种双重挑战导致模型极易过拟合或欠拟合,难以像LightGBM和RF算法那样能通过特征自动交互与集成学习更稳健地挖掘数据规律。综上,本文研究采用基于分类方案的LightGBM算法构建页岩储层类型识别模型。
3.3 测井曲线重要性
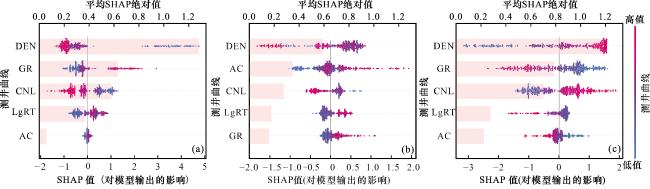
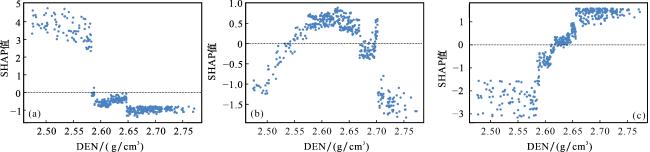
(1)I类储层识别:测井曲线的重要性排序为DEN、GR、CNL、LgRT及AC[图9(a)]。在最重要的3条曲线中,整体规律显示DEN和CNL取值越低、GR取值越高时,模型越倾向于将样本识别为I类储层。特征依赖关系图进一步表明[图10(a)],当DEN低于2.58 g/cm³时,SHAP值与DEN呈负相关(均大于2.6),说明DEN取值有利于识别为I类储层,但这种促进作用随DEN增大而减弱;当DEN超过2.58 g/cm³后,SHAP值陡然下降为负值,并分别维持在约-0.8(DEN<2.65 g/cm³)和-1.6(DEN>2.65 g/cm³)的水平,与DEN值不再呈现单调关系,表明此阶段DEN取值倾向于将样本识别为非I类储层。
(3)III类储层识别:测井曲线的重要性排序与其在I类储层识别中相同,即DEN、GR、CNL、LgRT及AC。在最重要的3条曲线中,整体规律表现为DEN和CNL取值越高、GR取值越低时,模型越倾向于将样本识别为III类储层。特征依赖关系图显示[图10(c)],当DEN小于2.58 g/cm³时,SHAP值与DEN几乎无相关性且均为负值,表明此时DEN取值抑制III类储层识别(倾向非III类储层);当DEN大于2.58 g/cm³时,SHAP值与DEN转为正相关关系,且在DEN超过2.61 g/cm³时,SHAP值由负转正,表明此阶段DEN取值开始促进模型将样本识别为III类储层。
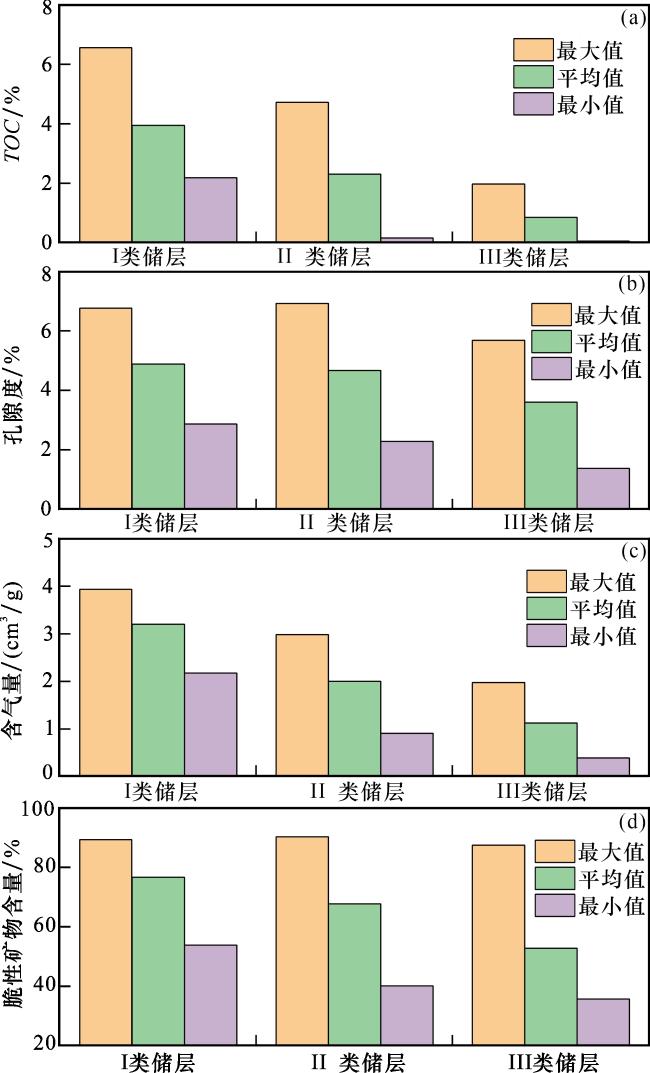
页岩储层中AC值的变化受多种地质因素共同控制,如TOC含量、矿物组成、孔隙度及含气性等。通常,高TOC含量、高孔隙度、高含气性及低脆性矿物含量会促使AC值升高。在研究区,与II类储层相比,I类储层具有略高的孔隙度、更高的有机碳含量和含气性(图11),这些因素倾向于推高AC值;然而,其极高的脆性矿物含量则强烈抑制AC值。最终,后者的主导作用使得I类储层的AC值低于II类储层。III类储层相较于II类储层更为致密,具有更低的孔隙度、有机碳含量和含气性(图11),这些因素引起的AC值降低效应,超过了因脆性矿物减少可能带来的AC值升高,导致III类储层的AC值为3类中最低。正是由于AC值在五峰组—龙一1亚段页岩中受多因素控制的复杂性,使其在识别II类储层时发挥了关键作用(图9)。
3.4 SHAP交互效应分析
交互效应是指特征之间协同作用对模型决策的影响,它剔除了特征单独作用(主效应)的部分,仅反映2个特征共同作用时对预测结果的增益或减益。因此,本文以I类储层的识别为例,分析测井曲线之间的交互效应对模型决策的影响。图12(a)展示了页岩储层类型识别模型中测井曲线间的交互效应强弱(非对角线),其中,DEN与CNL、DEN与GR、GR与CNL间的交互效应最强。因此,本文对上述3组交互效应进行重点分析。
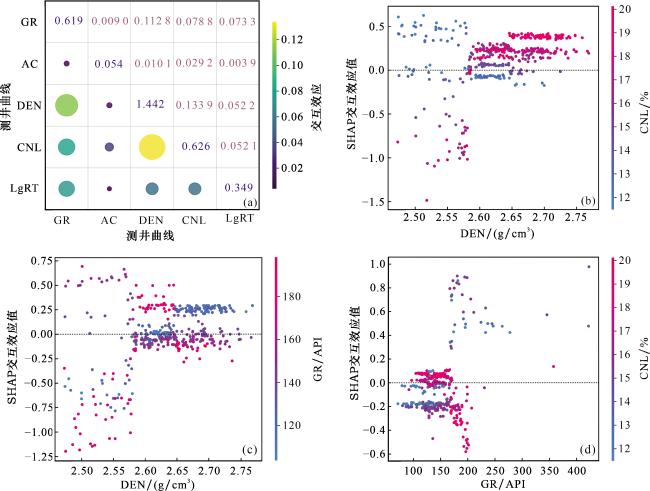
图12(b)展示了DEN与CNL的交互效应依赖图,可以看出,低DEN(<2.58 g/cm³)与低CNL(<13.5%)的交互效应值为正值,促使模型将样本预测为I类储层。这对应于低DEN—低CNL的典型测井相,表示高有机质及高孔隙度的页岩储层,是I类储层的核心特征。低DEN(<2.58 g/cm³)与高CNL(>13.5%)的交互效应值为负值,促使模型将样本预测为非I类储层。这对应低DEN—高CNL的测井相,表明页岩储层中可能富含流体或富含黏土矿物,降低了其作为I类储层的置信度。图12(c)展示了DEN与GR的交互效应依赖图,可以看出,在低DEN(<2.64 g/cm³)区域,只有当GR也为高值时(140~180 API),SHAP交互效应值为正值,表明低DEN和高GR对模型预测为I类储层具有极强的协同促进作用。当页岩同时具备低DEN(意味高孔隙度高有机质含量)和高GR(指示富铀有机质)特征时,模型会以最高的置信度将其识别为I类储层。在高DEN(>2.64 g/cm³)区域,GR值的变化对交互效应值的影响较小,位于0值附近,表明此时的交互效应对模型决策影响有限。图12(d)展示了DEN与GR的交互效应依赖图,可以看出,在高GR(>160 API)区域,当CNL值较低(<15%)时,SHAP交互效应值为较高的正值;而当CNL较高(>15%)时,SHAP交互效应值为较低的负值。这揭示了模型在富有机质层段(高GR值)内部的精细划分能力:高GR—低CNL指示富有机质的高孔隙度页岩,模型倾向于将其判为I类储层;高GR—高CNL可能指示富有机质但黏土含量也较高的层段,模型倾向于将其判为非I类储层。
4 页岩储层分级评价
5 结论
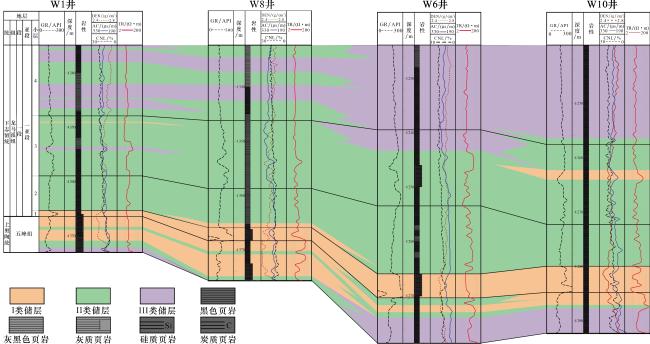
(1)在靶区的深层五峰组—龙一₁亚段识别出3类页岩储层,其中,I类储层(甜点段)的测井特征为高GR、低DEN、低CNL及较高AC;III类储层则具有低GR、高DEN、高CNL及低AC的特征;II类储层表现为中等GR、中等DEN、中等CNL及高AC。
(2)分类方案仅需构建一个分类模型即可实现深层页岩储层类型识别,在模型复杂度与计算效率上显著优于回归方案;同时,该方案避免了回归方案中多个储层参数预测误差的级联累积效应,从而提高了模型的识别精度和泛化能力。运用分类方案构建页岩储层类型识别模型,对于测试集数据,LightGBM算法对储层类型识别的Weighted-P为89.7%、Weighted-R为89.6%,其表现优于RF算法(Weighted-P及Weighted-R分别为87.52%和86.96%)以及SVM算法(Weighted-P及Weighted-R分别为83.61%和81.8%)。
(3)I类和III类页岩储层识别中,测井曲线重要性排序均为DEN>GR>CNL>LgRT>AC,而II类储层识别中,测井曲线重要性排序变化为DEN>AC>CNL>LgRT>GR。DEN是页岩中有机质含量与孔隙度2个核心地质属性的综合反映,故其在3类页岩储层识别中的重要性是最高的。SHAP依赖关系及交互效应分析显示,测井曲线对储层类型识别的影响呈现出复杂的非线性特性,测井曲线间的交互效应对模型决策产生了重要影响。
(4)将最优页岩储层类型识别方案应用于靶区深层页岩储层分级评价,结果表明I类储层主要分布于五峰组上部及龙一₁亚段1小层,在纵向上,页岩储层品质呈现五峰组向上逐渐变好、龙一₁亚段向上逐渐变差的趋势。
 甘公网安备 62010202000678号
甘公网安备 62010202000678号
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}