

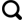
0 引言
非常规油气资源作为传统能源供给体系的重要补充,逐渐成为保障能源安全的战略性资源[1-2]。其中页岩储层作为非常规油气资源的重要载体,其分布广、储量大、赋存条件复杂,自21世纪以来在勘探开发技术革新与政策激励下实现规模化突破,页岩油气已成为全球能源领域的研究热点[3-6]。陆相页岩地层存在纵向上岩性变化快、岩石成分复杂、不同岩石类型测井响应特征差异小的特点,且细粒沉积物发育,黏土矿物、有机质等含量高,使得常规测井曲线响应受到干扰,人工测井解释方法多依赖经验公式、统计模型或人工判识,传统方法难以准确识别岩性[7],因此,迫切需要通过挖掘测井曲线与岩性特征之间的复杂映射关系,构建高精度、自适应的基于机器学习等方法的复杂岩性预测技术,来提升其识别精度。
近几年来,前人在机器学习预测岩性方面也取得较好的进展,武中原等[8]采用LSTM方法,通过提取岩性沉积序列特征提升了碳酸盐岩岩性识别精度,但该模型计算复杂、训练耗时,对长序列及岩性界面突变的响应仍显不足。周恒等[9]引入胶囊网络,利用其向量表达特性挖掘测井参数与岩性之间的深层关系,提高了识别精度,但该网络训练复杂、计算成本高,应用经验有限,稳定性易受影响。曹茂俊等[10]结合INPEFA技术、中值滤波与K-means聚类构建一维CNN模型,实现了地层识别与划分,但方法依赖预处理质量,K-means对噪声敏感且需预设类别数,难以捕捉复杂非线性特征。罗永亮等[11]提出改进的Stacking算法,融合多模型优势以增强特征提取能力,但模型结构复杂、训练成本高,模型选择不当易导致过拟合和可解释性降低。孙婧等[12]提出SSMO-SSA-LGBM模型,缓解了样本不平衡问题,但模型结构庞大、计算资源消耗高,决策过程复杂且可解释性较差。王勃等[13] 将KAN网络用于岩性识别,但该技术尚不成熟,易过拟合且缺乏真实测井数据验证,应用风险较高。尹琼[14]采用两步法及生成对抗网络处理类别不均衡问题,但存在误差累积风险,且GAN训练不稳定,可能生成噪声样本误导分类。王婷婷等[15]提出基于MSCNN-GRU与XGBoost的混合方法,增强了可解释性,但模型结构复杂、训练困难,曲线补全质量直接影响识别效果。秦志军等[16]采用递归特征消除与随机森林优选特征,提升了准确率与效率,但递归消除可能丢失弱相关或非线性重要特征。曹志民等[17]结合SMOTE与极端随机树应对样本不平衡问题,但SMOTE生成的合成数据可能不符合实际地质规律,对边界模糊岩性提升有限。从目前的研究现状来看,基于机器学习的方法有效地提高了岩性识别的效率。但已有成果所用到的机器学习模型局限于测井数据,尤其针对垂向非均质性强、岩性变化快、成分复杂的陆相页岩[18-19],其不同岩性的测井响应特征相似性高,难以实现岩性的精确判别,更多的机器学习算法只关注到了数据的单一特征,未能发掘数据中的关联性和潜在信息。
本文以鄂尔多斯盆地L井区延长组7段(长7段)为研究对象,基于筛选出对岩性响应明显的测井参数作为输入特征,构建一种融合注意力机制的双向长短期记忆网络(BiLSTM-Attention)有监督学习模型,对三叠系延长组陆相页岩储层岩性进行预测,相较于传统机器学习模型,该模型显著优势在于其双向结构与注意力机制的有机结合,双向机制捕捉了测井数据中上下岩性段相关的序列依赖关系。同时,注意力机制通过对这些上下岩性信息的自动加权,使模型能够动态聚焦于对当前岩性分类最关键的测井响应特征层段,从而有效克服了因岩性频繁互叠导致的特征模糊难题。通过这一协同作用,共同增强了模型对强非均质性页岩储层复杂岩性序列的解译能力。该研究可为陆相页岩储层岩性识别提供可靠方法,同时为复杂储层岩性分析提供新的思路。
1 方法
1.1 BiLSTM-Attention原理
(1)输入门(Input Gate)更新细胞状态的候选值,控制测井序列中新生信息的流入,判断新岩层界面的声波时差、自然伽马等特征是否值得被模型记忆。
式中: 是输入门的输出,控制候选细胞状态 有多少被加入到当前细胞状态; 是候选细胞状态,由当前输入和上一时刻隐藏状态计算得出; 分别是输入门和候选状态的权重矩阵; 、 是对应的偏置项; 是激活函数,将值压缩到(-1,1)。
(2)遗忘门(Forget Gate)决定丢弃哪些历史信息,使模型能够主动遗忘无关的上下岩层信息,在岩性转换时减弱前序岩性特征的干扰,以聚焦于当前界面的关键响应。
式中: 为遗忘门的输出,取值范围在0到1之间,决定要保留多少上一时刻的细胞状态; 是sigmoid 激活函数,将输出压缩到(0,1); 是遗忘门的权重矩阵; 是将上一时刻的隐藏状态 和当前输入 拼接成一个向量; 是遗忘门的偏置项。
(3)输出门(Output Gate)决定当前时刻的输出,调控当前时刻应输出的状态信息,决定将哪些关键的岩性特征传递至后续序列,以影响对下层岩性的识别。
式中: 是输出门的输出,控制当前细胞状态 有多少信息输出到隐藏状态 分别是输出门的权重矩阵和偏置; 是当前时刻的隐藏状态,也是该时刻的输出; 是当前时刻的细胞状态,是LSTM的记忆。 是遗忘门控制保留多少旧记忆; 是输入门控制加入多少新信息。
BiLSTM是在LSTM模型基础上的改进版本,BiLSTM(BidirectionalLongShort-TermMemory)是一种结合了前向和后向LSTM层的循环神经网络结构(图1),在处理测井曲线任务中相比于LSTM优势在于其通过结合前向(过去到未来)和后向(未来到过去)2个LSTM层[21],其中,每个LSTM单元通过其输入门、遗忘门与输出门,有选择性地记忆或忽略测井序列中不同深度的岩性特征,而双向结构使模型能够同时分析目标层段的上、下岩性信息,采用这种双向结构,模型能够在任何一个深度点,同时获取其上方和下方的全局序列信息,从而精准建模岩层顶底界的测井响应特征以及薄互层之间的复杂交互关系。在实际测井曲线中,每一个深度点被视为一个时间步,多种测井参数构成该时间步的特征向量,而深度方向则构成了序列的时间轴,BiLSTM算法在处理测井曲线时有较好的适用性。
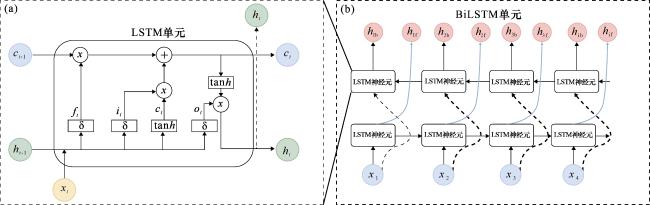
由于BiLSTM算法自动聚焦于测井曲线中关键特征点能力较弱,所以将BiLSTM算法融合了注意力机制,以提高有用特征在模型训练过程中的作用,注意力机制通过对BiLSTM层输出的隐藏状态进行加权处理,给予关键特征较高的权重,而对次要信息赋予相对较低的权重。这种机制能在复杂数据环境中聚焦于最重要的特征,以过滤冗余信息,提高决策的准确性[22]。尽管BiLSTM能捕捉双向上下文,但其输出是所有时间步特征的简单拼接或平均,无法动态区分不同位置特征的重要性,Attention为每个时间步分配权重,通过计算当前深度(Query)与测井序列中所有位置数据(Key-Value)的关联性,为不同层段的特征分配差异化的权重,从而自动聚焦于对岩性分类最关键的测井响应区间。对于Attention层输入数据通常包含3部分,分别为查询向量、键向量集合、值向量集合(图2)。
(1)查询向量 )表示当前需要关注的目标(测井曲线中的某个深度点)。
(2)键向量集合[ )]与查询交互的候选特征(测井曲线中所有深度点的特征)。
(3)值向量集合 )]实际用于加权求和的特征。
1.2 BiLSTM-Attention模型架构参数与优化
1.2.1 网格参数
通过实验设计,构建了具有注意力机制的双向长短期记忆网络模型(BiLSTM-Attention),BiLSTM-Attention模型网格参数主要包含以下6个方面。①输入层:在测井参数深度序列中,设置滑动窗口大小为50个时间步长,特征维度为6。②BiLSTM层:其隐藏单元数初步设置为64个LSTM小单元组成,模型设计为双向结构,其中前向LSTM参数量为134 144[该处的参数量指导的是参与神经元运算的单向传播数,计算公式:前向LSTM: 4×(128×(特征数+128)+128)],后向参数量同前向LSTM参数,所以总参数量为268 288,在LSTM层之间应用Dropout以防止过拟合,其中Dropout丢弃率设置为0.2。③注意力层:注意力层输入来自BiLSTM层输出数据,为模型注入的是加性注意力机制,其中注意力维度位64层,作用为用于计算注意力得分的全连接层维度,注意力层输出的参数形状和输入相同。④特征融合层:注意力输出+BiLSTM序列均值池化。目的是将注意力机制获取的权重参数合理分配给参与运算的特征值,融合层的输出维度为262(注意力展平后+池化特征)。⑤全连接层:神经元数为64个,使用的激活函数为ReLU。⑥输出层:激活函数为Softmax,输出维度为5(对应5种岩性,如:泥岩、页岩、粉砂质泥岩、泥质粉砂岩、粉砂岩)。
1.2.2 训练参数
初步设定100个训练轮次以确保模型充分收敛,同时采用64的批次大小在训练稳定性和内存效率之间取得平衡。优化方面使用自适应学习率的Adam优化器配合默认0.001学习率,同时引入早停机制以优化训练过程与提升模型泛化能力。具体地,笔者监控验证集上的损失性能,当其连续5个epoch未出现改善时,则提前终止训练,并回滚至最优权重,有效避免了模型在训练数据上的过拟合。模型泛化能力通过每轮训练后在占总体30%的独立验证集上进行准确率评估来监控。数据处理阶段采用30个时间步长的滑动窗口将测井数据转化为适合时序模型处理的序列格式。实验可重复性由固定随机种子42保证,确保每次运行都能获得一致的数据划分和初始化结果。整个训练过程还集成了双重Dropout正则化策略,分别在BiLSTM层后设置0.2丢弃率和全连接层后设置0.3丢弃率,进一步增强模型的鲁棒性。
1.2.3 优化策略
本文主要采用网格搜索与手动微调相结合的策略,第一步主要对网格进行粗调,接下来在第一步的基础上对网格进行精细化调整,以下为具体设计方案和优化过程。
第一步:使用网格搜索在较大的参数空间(如隐藏单元数和学习率)进行初步筛选。固定其他参数(如层数为1,Dropout为0.2),遍历不同隐藏单元数和学习率的组合,以验证集准确率为指标,快速定位性能较优的区域。第二步:在粗调确定的大致范围内(例如,发现隐藏单元128和256、学习率0.001和0.000 1表现较好),进行更精细的手动调参。此时,同时调整层数和Dropout率,观察模型在验证集上的准确率和损失曲线,防止过拟合或欠拟合。
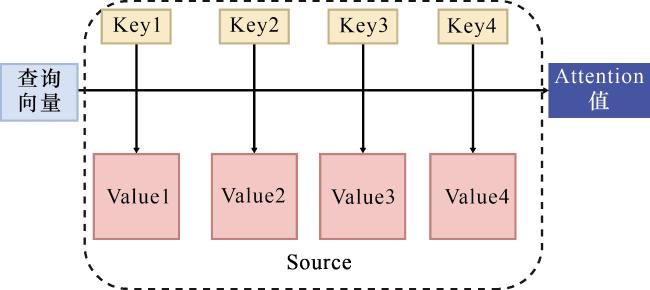
对模型的具体优化过程与决策依据分为以下3个内容,①隐藏单元数与层数:当隐藏单元从64增加到128时,验证集准确率显著提升(约3%)。当增加到256时,准确率仅微幅提升(约0.5%)(图3),但训练时间几乎翻倍,且更易出现过拟合迹象(验证集损失开始波动并上升)。因此,选择128作为隐藏单元数。同样,层数从1增加到2时,模型捕获深层上下文信息的能力增强,准确率提升;当增加到3层时,模型变得难以训练,梯度不稳定,且过拟合风险加剧,故选择2层。②Dropout率:Dropout率为0.2时,模型在训练集上收敛很快,但在验证集上的表现不稳定,存在过拟合。当增加到0.3时,验证集准确率最稳定且最高。当增加到0.5时,模型正则化过强,导致训练不足,准确率下降。因此,选择0.3作为最佳Dropout率。③学习率与批处理大小:学习率0.1和0.01导致损失振荡无法收敛。0.001和0.000 1均能稳定收敛,但0.001收敛速度更快,最终准确率略高。结合学习率衰减策略,选择0.001作为初始学习率。
1.3 BiLSTM-Attention模型工作流程
基于BiLSTM-Attention的测井曲线岩性识别主要分为3个模块,第一步进行原始测井数据处理,在预处理中首先通过测井曲线箱型图进行异常值处理,接下来通过皮尔逊相关系数法优选出敏感性高的测井参数,最终对所有测井曲线进行归一化以消除量纲差异,并将数据集划分为训练集和测试集。第二步进行模型训练阶段,使用训练集构建并优化一个结合了双向长短期记忆网络(BiLSTM)和注意力机制(Attention)的深度学习模型,训练过程中设有异常监控机制,实时检测并处理损失异常、性能退化等问题,确保训练稳定,同时,根据模型在验证集上的最佳表现(如最高准确率或最低损失)保存最优模型。第三步利用保存的最佳模型对全新的、独立的测井数据进行预测和性能验证,评估其实际泛化能力与应用效果(图4)。
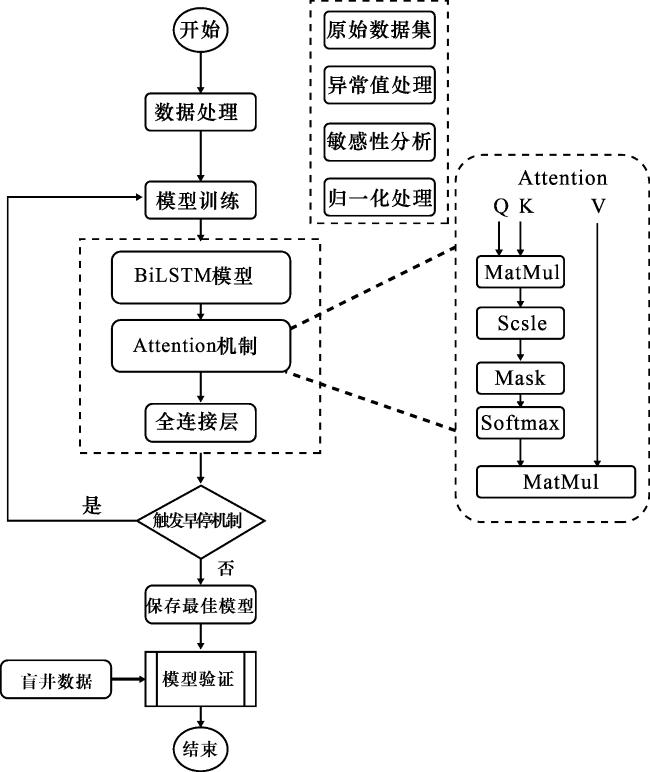
2 应用实例与实验结果
2.1 研究区概述
鄂尔多斯盆地为典型的克拉通盆地,依据其现今的构造形态,鄂尔多斯盆地自西向东划分为天环坳陷、西缘冲断带、晋西挠褶、渭北隆起、伊陕斜坡和伊盟隆起6个一级构造单元[23],研究区L井区构造上位于伊陕斜坡带中部,该构造单元构造简单,主要发育坡度平缓的西倾单斜构造,且局部发育鼻状隆起[24]。晚三叠世长7段沉积期为鄂尔多斯盆地内陆坳陷湖盆发育的鼎盛期,在淡水半深湖—深湖区沉积了一套富有机质泥页岩、灰色泥岩夹薄层粉砂岩—细砂岩为主的泥页岩层系,其岩性空间上变化大,平均厚度约为105 m,是盆地内最重要的页岩油发育层段[25-26]。长7段自上而下被分为3个亚段:长71、长72、长73亚段,本次主要针对长73亚段油页岩层系,该层厚度一般在45 m[27],区域广泛且稳定分布,有机质丰度高,为鄂尔多斯盆地重要的页岩油产层[28-30]。
2.2 测井参数处理
研究数据来自鄂尔多斯盆地延长组L井区8口井,主要层系为长7段,所用到的测井资料包含3 053个采样点。每个采样点记录了不同测井方法获得的8个测井序列的参数分别为自然伽马、密度、声波时差、自然电位、光电吸收截面指数、井径、深侧向电阻率和深侧向电阻率,每个样点对应一类岩性,其中包括页岩、粉砂岩、泥质粉砂岩、粉砂质泥岩、泥岩,实验选取每个钻孔中的70%采样点作为训练集,30%作为测试集进行数据集构建。
2.2.1 测井参数异常值处理
针对鄂尔多斯盆地测井资料的分析,本研究对研究区测井参数异常值进行处理,研究区长7段主要发育泥岩、页岩、粉砂质泥岩、泥质粉砂岩和粉砂岩等5种岩性。通过对测井参数箱型图进行分析,识别测井数据的统计分布特征及异常值,有助于优化BiLSTM-Attention模型的输入数据质量、关键特征权重分配,并识别岩性敏感区间,从而增强复杂储层岩性序列预测的鲁棒性与地质可解释性。
箱型图中以不同颜色区分不同岩性类型,每个箱体展示了相应测井参数在该岩性中的分布情况,包括中位数、四分位数等统计信息,上下须线则反映数据分布范围。通过对比不同岩性箱体的位置与长度,可揭示测井参数在各岩性中的差异特征(图5)。
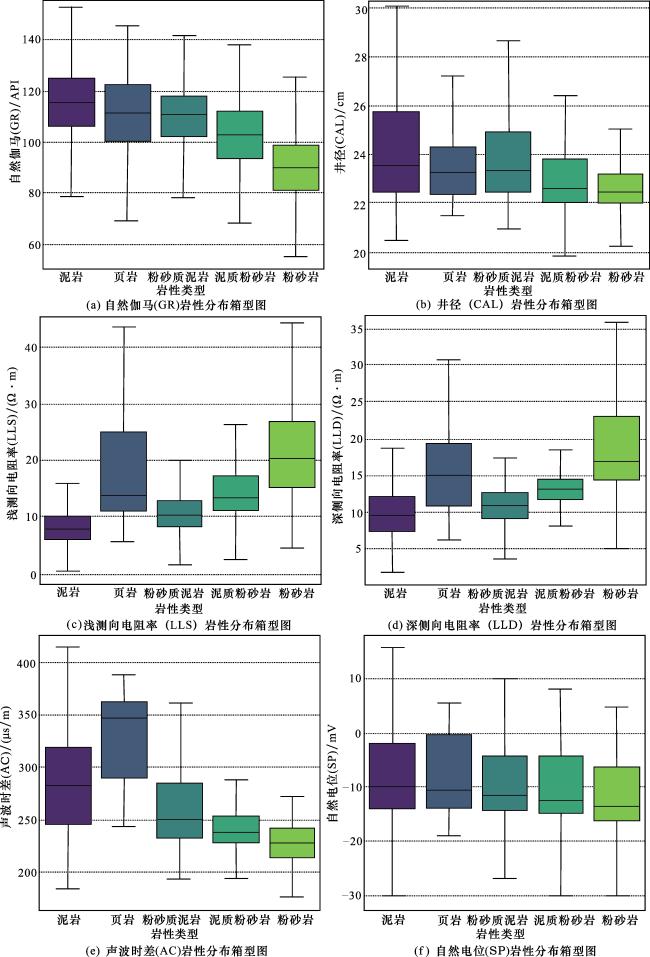
以L1井为例,不同岩性在各类测井属性上表现出明显差异的响应特征。总体来看,泥质岩类的自然伽马与井径值普遍较高,而非泥质岩性的自然伽马值相对较低,因此可利用这2个参数有效区分泥岩与其他岩性。此外,页岩不仅具有较高的自然伽马响应,其声波时差和自然电位测井响应也普遍高于其他岩性,可作为识别页岩的关键指标。
受数据噪声影响,部分岩性对应的测井参数值分布范围较宽,且存在离群值。这些异常值主要影响箱线图的上下边界,但对中位数及四分位数的影响较小。为更准确地统计具有地质意义的测井响应特征范围,本研究采用第95百分位数和第5百分位数分别作为岩性响应有效区间的上限与下限(表1)。
表1 鄂尔多斯盆地延长组L井不同岩性异常值处理后的测井参数响应特征Table 1 Logging parameter response characteristics after abnormal value processing of different lithologies in Well L of the Yanchang Formation, Ordos Basin |
| 岩性 | AC/(μs/m) | GR/API | CAL/cm | SP/mV | LLD/(Ω·m) | LLS/(Ω·m) |
|---|---|---|---|---|---|---|
| 粉砂岩 | 174~420 | 55~126 | 20.32~27.94 | -30.2~5 | 5~37 | 4.5~45 |
| 泥质粉砂岩 | 193~419 | 63~138 | 19.56~26.4 | -30~9 | 3.6~18 | 2.5~27 |
| 粉砂质泥岩 | 193~393 | 60~141 | 21.1~28 | -27~10 | 3.2~17 | 1.8~20 |
| 泥岩 | 184~426 | 79~158 | 21~30 | -30~14 | 2~18 | 0.8~17 |
| 页岩 | 230~394 | 70~150 | 22~27.4 | -18~5 | 6~53 | 5~43 |
2.2.2 测井参数敏感性分析
预测储层岩性通常涉及多种测井曲线,如自然伽马、声波时差、体积密度等,由于不同岩性与各类测井曲线的数值范围和尺度差异较大,直接使用这些数据可能会导致某些特征在模型中占据主导地位,从而降低模型的准确性和泛化能力。皮尔逊相关系数法在岩性识别中作为一种高效、定量的初步筛选工具,用于优选出对岩性变化最敏感的测井参数,其核心原理是通过计算各条测井曲线(如GR、AC、DEN等)与已知岩性标签之间的线性相关系数,来定量评估每条曲线对岩性区分能力的强弱,其取值范围为-1到1之间,绝对值越高的参数被视为关键敏感参数。图6是对研究区测井参数敏感性分析的结果。
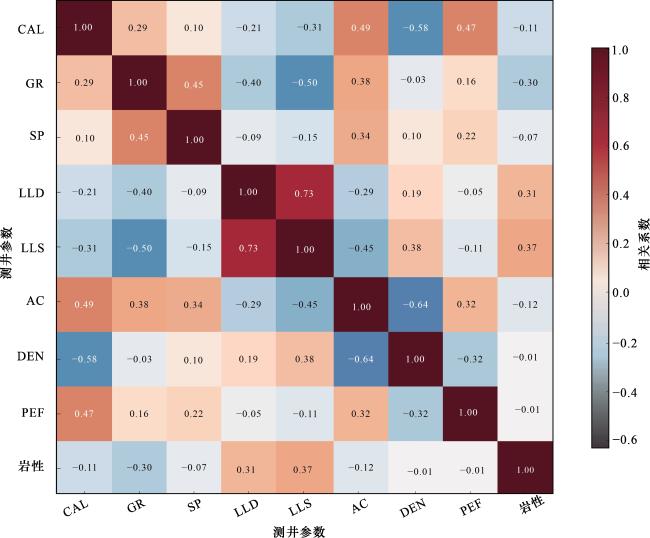
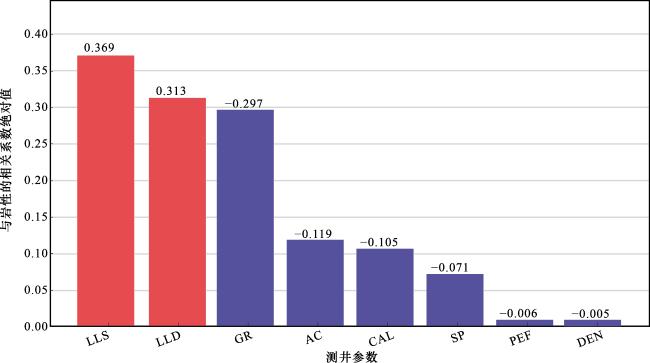
通过对以上皮尔逊相关系数矩阵分析可知,密度和光电吸收截面指数与岩性的相关系数非常低,相关系数绝对值约为0.01,其中深侧向电阻率和深侧向电阻率对岩性识别的敏感性较高,分别为0.31和0.37,对于自然伽马、声波时差、自然电位和井径4种测井参数对岩性识别的敏感性贡献值相对密度和光电吸收截面指数较高,图7更直观地反映了测井参数对岩性识别敏感性,其中深侧向电阻率和深侧向电阻率呈正相关,其他测井参数均呈负相关,条形图反映了各参数取绝对值后的相关值大小,最终优选出了自然伽马、声波时差、自然电位、井径、深侧向电阻率和深侧向电阻率等6种高敏感性参数作为模型的输入值。
2.2.3 测井参数归一化处理
经过上述测井参数的异常值处理和敏感性分析,获取了合理的测井参数值,为了统一数据的尺度,需要在实验前对测井数据的尺度进行归一化处理。对原始数据进行线性变化操作,并映射到[0,1]范围。归一化函数如(6)所示[31]。
式中: 为原始数据值; 为数据集X中的最小值; 为数据集X中的最大值; 为归一化后的值,在[0,1]区间内。
2.3 BiLSTM-Attention模型性能分析
在分类预测任务中,性能度量是评估模型预测效果的标准,为了评估BiLSTM-Attention模型在研究区表现性能情况,实验引入准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数对模型性能进行评估,上述性能指标表达式如下:
式中:TP为正确预测为正类的岩性数量;TN为正确预测为负类岩性数量;FP为错误预测为正类的岩性数量;FN表示错误预测为负类的岩性数量[32]。
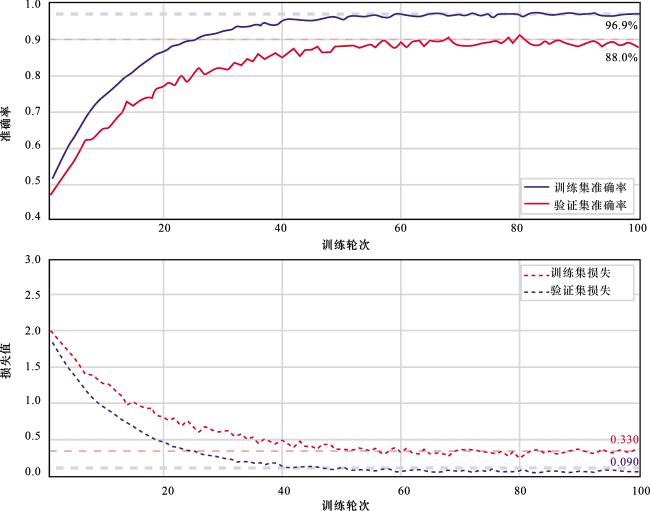
首先探究BiLSTM-Attention模型在L1井预测时的准确率,从图8可以看出,BiLSTM-Attention模型在训练集上的分类准确率随训练迭代次数增加而持续上升,最终在训练次数为100EPOCHS呈现稳定趋势,该模型的最优训练准确率达到0.969,验证集准确率为88%,同时训练集损失函数值达到0.09,因此反映出了模型的预测结果与实际值非常接近,所以BiLSTM-Attention模型预测储层岩性类别具有较高的准确率。
为评估BiLSTM-Attention模型的实际性能,将其与BiLSTM、LSTM、CNN和SVM算法在L1井岩性识别效果上进行对比。其中,BiLSTM-Attention、BiLSTM、LSTM和CNN均采用100EPOCHS次数进行训练,SVM算法在使用5折交叉验证时达到最优性能,同样,其他4种模型在100EPOCHS次数时也达到最优性能,确保了实验对比的合理性。实验结果表明,BiLSTM-Attention模型在训练准确率与验证准确率上均优于其他对比模型(表2)。
表2 研究区L1井不同机器学习模型的岩性识别评估Table 2 Lithology identification evaluation of different machine learning models for Well L1 in the study area |
| 模型评估 | BiLSTM-Attention | BiLSTM | LSTM | CNN | SVM |
|---|---|---|---|---|---|
| 训练准确率/% | 96.9 | 92.95 | 91.18 | 84.85 | 88.4 |
| 验证准确率/% | 88 | 85.4 | 83.6 | 73.45 | 76.5 |
| 损失值 | 0.09 | 0.2141 | 0.2431 | 0.280 0 | 0.262 2 |
| 迭代次数 | 100(EPOCHS) | 100(EPOCHS) | 100(EPOCHS) | 100(EPOCHS) | 5(FOLDS) |
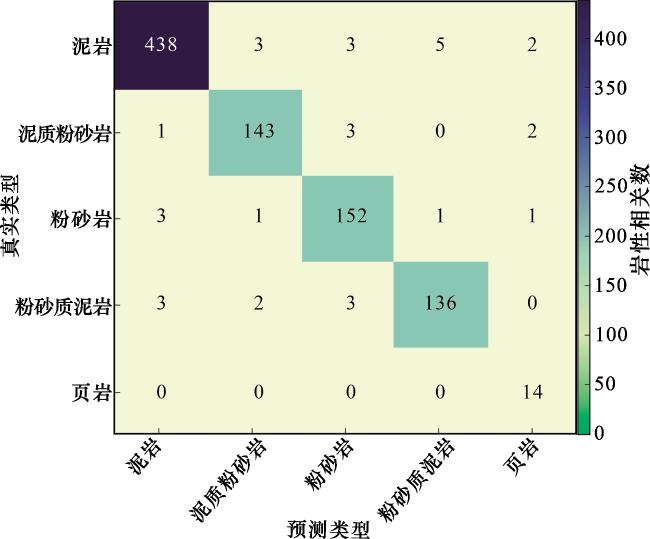
接下来通过双参数结果混淆矩阵分析BiLSTM-Attention模型在L1井的识别精确率、召回率、F1分数等3种性能指标,从图9中可以看出,泥岩有3个被误判为泥质粉砂岩,5个为粉砂质泥岩,3个为粉砂岩,2个为页岩,泥岩被误判为相邻岩性的根本原因在于地质实体在成分与结构上的连续性导致了测井响应的广泛重叠,泥岩与页岩在常规测井曲线上均表现为高自然伽马、高声波时差的特征,其与粉砂质泥岩、泥质粉砂岩的混淆源于GR值对泥质含量变化的连续响应,使过渡岩性的测井特征落入泥岩的典型范围,其测井曲线呈现出频繁的微齿状波动或低幅指状尖峰,反映了一定比例的粉砂质成分,可能造成岩性混淆,而与粉砂岩的误判因成岩作用或井眼垮塌使泥岩的GR值失真、砂岩化,测井曲线整体形态表现为光滑的钟形,与纯净粉砂岩的典型特征极为相似。泥质粉砂岩中有1个被误判为了泥岩,3个为粉砂岩,2个为页岩,泥质粉砂岩被误判的核心在于其作为典型过渡岩性,其测井响应构成了连接泥岩与粉砂岩的连续谱系:当泥质含量增高或具放射性时,其高GR值易被误判为泥岩或页岩,泥质粉砂岩自然伽马呈现中高值且曲线齿化严重,电阻率表现为中低阻背景上的频繁波动,与富含有机质的页岩和泥岩特征高度重叠,影响岩性识别,当泥质含量降低或经受钙质胶结时,其低GR与致密特征又易被误判为粉砂岩,而与粉砂质泥岩的混淆,则源于二者在成分比例临界点处测井响应的固有重叠。粉砂岩中有3个被误判为泥岩,1个泥质粉砂岩,1个粉砂质泥岩,1个页岩,当粉砂岩中含有大量放射性矿物时,其自然伽马值会异常升高,达到页岩级别,泥质的加入会使得粉砂岩的声波时差(AC)增大这种泥质化效应使其在多种测井曲线上的响应与粉砂质泥岩高度重叠,模型难以区分这种成分上的细微差别。粉砂质泥岩中有3个被误判为泥岩,2个为泥质粉砂岩,3个为粉砂岩,误判的原因与泥质粉砂岩相似。其中页岩识别的召回率达到99%,泥岩为95%,泥质粉砂岩为93.2%,粉砂岩为93%,粉砂质泥岩为91%。较高的召回率表明了该模型能够有效地识别大部分真实正类样本,说明模型对正类样本的敏感度较高,这在需要高灵敏度的岩性识别应用中尤为重要。
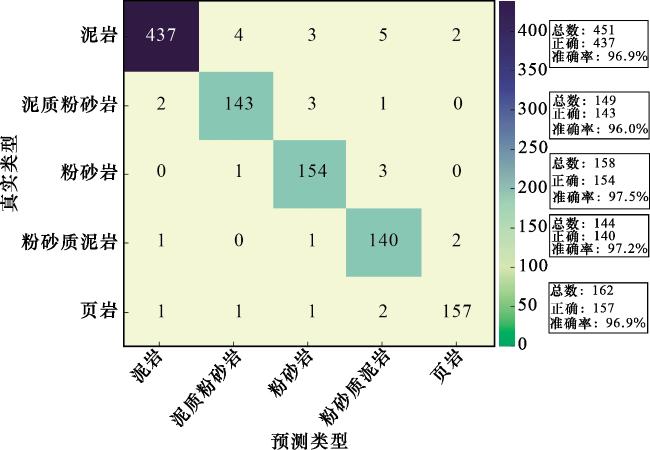
从上述表3中可以看出,页岩的样本数量仅为14个,其召回率达到了0.99,相比于其他岩性种类,页岩岩性样本过少,为了避免样本数量不均衡问题对实验结果造成的影响,进行补充实验,然而在实测样本数量中无法直接增加页岩样本数量集,所以考虑采用SMOTE方法平衡样本数量集。
表3 L1井岩性预测指标Table 3 Lithology prediction metrics for Well L1 |
| 指标 | 准确率 | 召回率 | F1分数 | 样本总数/个 |
|---|---|---|---|---|
| 泥岩 | 0.97 | 0.95 | 0.934 | 451 |
| 泥质粉砂岩 | 0.95 | 0.932 | 0.91 | 149 |
| 粉砂岩 | 0.96 | 0.93 | 0.954 | 158 |
| 粉砂质泥岩 | 0.939 | 0.91 | 0.92 | 144 |
| 页岩 | 0.99 | 0.99 | 0.985 | 14 |
2.3.1 SOMTE方法
SMOTE是一种用于解决分类问题中类别不平衡的经典算法,SMOTE的核心理念是插值,它认为特征空间中2个相似的少数类样本之间,其连线上的点也很有可能是合理的少数类样本。因此,在这些样本点之间进行插值来创造新的、多样化的合成样本,而不是简单地复制已有的数据。主要目标是通过人工合成新的少数类样本来增加其数量,从而使不同类别的样本量达到平衡,提升机器学习模型对少数类的识别能力。通过对页岩样本的测井参数和岩性标签进行SMOTE插值,最终使页岩样本数量与其他岩性样本数量保持平衡,对差值后的样本数量重新进行混淆矩阵分析。
表4 L1井岩性预测指标Table 4 Lithology prediction metrics for Well L1 |
| 指标 | 准确率 | 召回率 | F1分数 | 样本总数/个 |
|---|---|---|---|---|
| 泥岩 | 0.969 | 0.95 | 0.934 | 451 |
| 泥质粉砂岩 | 0.96 | 0.942 | 0.93 | 149 |
| 粉砂岩 | 0.975 | 0.962 | 0.954 | 158 |
| 粉砂质泥岩 | 0.972 | 0.96 | 0.952 | 144 |
| 页岩 | 0.969 | 0.953 | 0.965 | 162 |
| 均值 | 0.969 | 0.9534 | 0.947 | 213 |
2.4 实验结果
本节分别采用传统的机器学习模型和作者提出的BiLSTM-Attention模型对研究区L1井进行盲井分类预测,在传统机器学习模型中选择BiLSTM、LSTM、支持向量机(Support Vector Machine, SVM)、卷积神经网络(Convolutional Neural Network, CNN)4种机器学习模型。图11展示了5种机器学习模型对研究区L1井岩性识别结果。
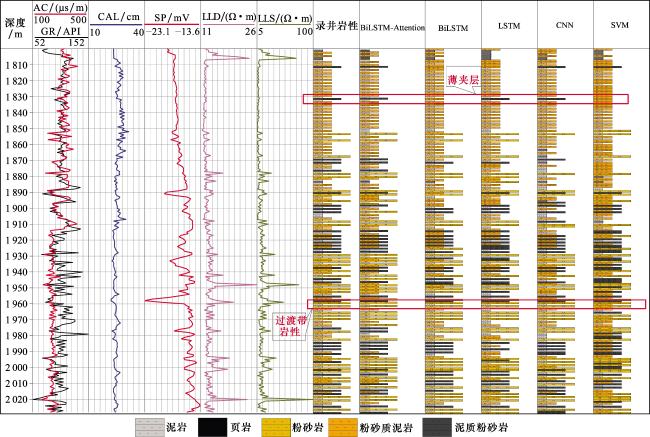
传统机器学习模型在页岩储层复杂岩性识别任务中,其岩性识别效果不佳,主要表现在对于复杂的过渡带岩性和薄夹层识别不准确,对储层的精细岩性划分不精确。从图11中可以看出,在L1井1 830 m深度点时,BiLSTM和SVM模型对页岩夹层的识别效果差,而BiLSTM-Attention模型精准捕捉到了这个页岩夹层,在1 960 m深度点时,LSTM和SVM很难精准地判断过渡带岩性,而BiLSTM-Attention模型通过双向结构算法清晰地识别了过渡带岩性,其中CNN模型在页岩储层复杂岩性识别中整体识别准确度低。作者提出BiLSTM-Attention模型通过结合前向和后向信息进行岩性识别,同时Attention机制自动聚焦于测井曲线中的关键特征点,其岩性识别准确率达到96.9%,相较于传统BiLSTM模型的92.95%高出4个百分点,表明了BiLSTM-Attention模型在页岩岩性分类任务中有较强的综合性能。
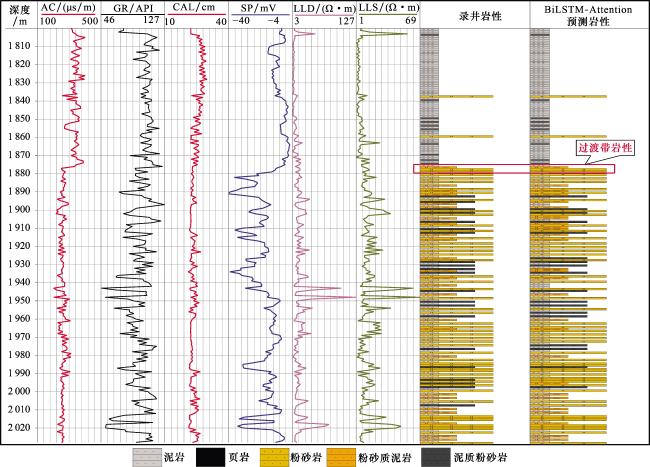
图12 研究区L2井 BiLSTM-Attention模型识别岩性结果Fig.12 Lithology identification results of the BiLSTM-Attention model for Well L2 in the study area |
在L2井中,对于过渡层,BiLSTM能够看到当前深度点之上(浅部)和之下(深部)很长一段序列的信息。从图12中可以看出,在L2井1 885 m深度点时,岩性由泥岩→粉砂质泥岩→粉砂岩过渡的序列时,它不仅能记住之前遇到的典型泥岩特征,还能预见到即将出现的粉砂岩特征。这种双向的上下文信息,使得模型能够更准确地判断当前点处于过渡带的哪个阶段,而不是孤立地将其误判为某一种纯岩性,在识别一个渐变序列时,Attention机制显示出一种权重转移的模式。在从泥岩到粉砂岩的过渡带起点,模型可能更关注与泥岩相关的上下文。随着深度增加,其注意力焦点会逐渐转移到与粉砂岩更相关的信号上。这种动态的注意力分配,完美地契合了岩性渐变的本质。
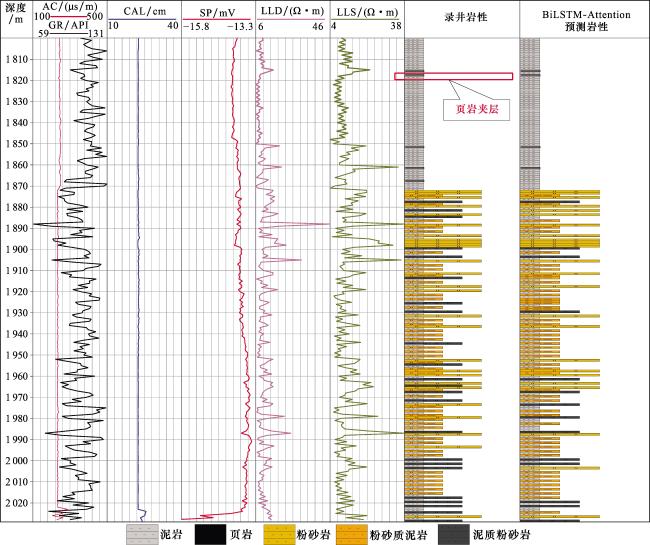
在L3井中(图13),对于薄夹层,在L3井1 820 m深度点时,一个薄页岩夹层在泥岩中,其测井响应(如伽马值升高)可能只持续几个采样点。单向LSTM可能只记住了之前大段泥岩的信息,而忽略了之后迅速回归泥岩的线索。BiLSTM则能同时利用夹层上方泥岩和下方泥岩的信息,来确认中间这个异常信号是一个局部的、薄层的特征,从而更精确地圈定其顶底边界,薄夹层的测井响应信号微弱且短暂。然而在传统的模型中,这些点的信息可能会被序列中大量正常点的信息所稀释。同时Attention机制可以学习到,在判断该深度点的岩性时,应该给这个薄夹层本身及其边界附近的数据点分配极高的权重。这意味着模型会主动聚焦和放大这些关键但微弱的信息,极大地提升了信噪比,使薄夹层在特征空间中变得突出。
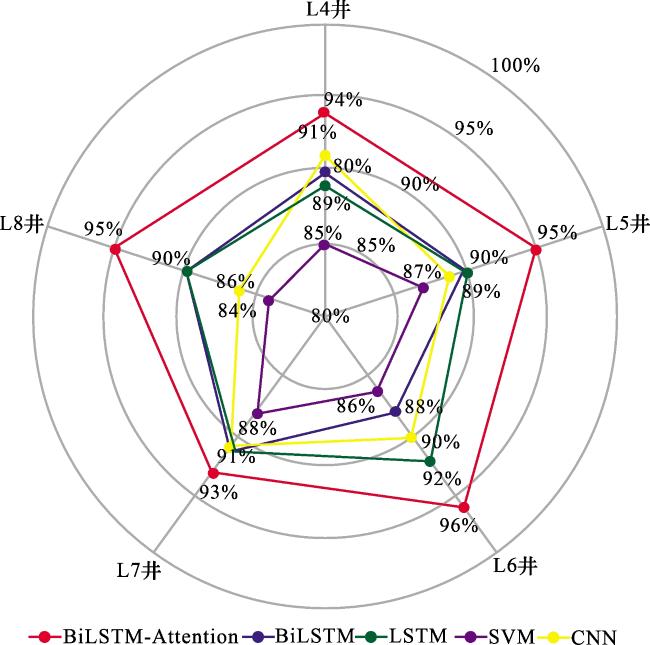
为了避免实验数据的偶然性,分别通过BiLSTM-Attention、BiLSTM、LSTM、SVM及CNN 5种模型对剩余5口井进行岩性预测,预测结果如图14所示,结果表明:BiLSTM-Attention模型预测准确率高,与上述L1、L2、L3井测试结果基本吻合,表明BiLSTM-Attention模型在复杂页岩储层的岩性识别中应用性较强。
3 结论
(1)本文基于皮尔逊相关系数矩阵对鄂尔多斯盆地延长组长73亚段L区页岩储层测井数据进行分析,优选出了AC、GR、SP、CAL、LLD和LLS共6种敏感性较高的测井参数作为模型输入值,同时采用SMOTE方法解决了岩性样本不均衡问题,最终构建出泛化性强、识别精度高的BiLSTM-Attention岩性分类模型。
(2)本文所采用的BiLSTM-Attention模型在识别复杂页岩储层岩性准确率高、损失值小,该方法相较于BiLSTM、LSTM、SVM、CNN传统单一的机器学习模型,BiLSTM-Attention模型岩性综合识别准确率高出4.05%~8.5%,尤其在复杂页岩储层中对于薄夹层和过渡岩性的识别效果好,其准确率和召回率分别提升了6.9%和5.6%,验证了该模型的有效性,该方法对复杂储层岩性精细化识别有重要指导意义。
(3)BiLSTM-Attention模型有望成为页岩储层智能化、精细化岩性识别的关键技术,但在复杂储层岩性识别的应用仍面临一些挑战,未来研究应着重于开发鲁棒性强、轻量化的架构,探索半监督学习和岩石物理信息约束的结合,实现在少样本岩性识别中的应用。
 甘公网安备 62010202000678号
甘公网安备 62010202000678号
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}