

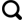
0 引言
在储层地质建模领域中,地质统计学是建立地下地质模型非常重要的数学工具。20世纪90年代以前,传统建模方法主要是以变差函数为基本工具再现研究对象的统计特征和空间相关性。由于地下地质条件的复杂性,变差函数刻画的两点统计难以表征曲流河等复杂地质体的空间结构[1,2,3,4]。90年代多点地质统计学算法(MPS)应运而生,多点地质统计学使用训练图像代替变差函数来表征地质体的空间相关性[5]。训练图像是一种先验地质模式,多点统计模拟过程实际上就是对训练图像中地质模式再现的过程。在每个网格点的模拟过程中,GUARDIANO等[5]提出的多点统计模拟算法都需要遍历整个训练图像来寻找最优解,因此整个模拟过程非常耗时,使得该算法难以实际应用。STREBELLE[6,7]提出采用搜索树的数据结构存储数据事件,通过这种方式整个模拟过程只需要扫描一次训练图像,在后续模拟中待模拟网格点的累计概率分布函数直接由搜索树得到。这个方法大大提高了多点统计模拟的效率,使得多点地质统计学进入实用阶段。GUVEN提出了SIMPAT算法[8],不同于基于概率的方法,SIMPAT方法首先把训练图像中的全部样式建立一个样式库。在模拟时寻找与数据事件最相似的数据样式,将得到的数据样式整体覆盖到待模拟网格点处,解决了基于概率的多点地质统计学方法存在的非平稳性问题。在进行三维模拟时,由于提取的数据样式数量巨大,且模拟过程中需要计算数据事件与每一个数据样式的相似度,因此计算量非常大,难以满足实际应用。ZHANG等[9]提出一种针对SIMPAT的改进方法(FLITERSIM),FLITERSIM方法在模拟之前使用一系列过滤模板扫描训练图像,在训练图像上的每个节点都能得到一组“过滤分数”,然后依据“过滤分数”对训练图像中提取到的数据样式进行聚类。该方法在实际应用过程中如何选择合适的过滤模板是个难点。GREGOIRE提出一种直接抽样模拟方法(DS)[10,11],它是一种基于像元的多点统计模拟方法。DS方法在模拟时,不需要扫描整个训练图像。DS方法设定一个相似度阈值,在对比数据事件与数据样式相似度时,一旦二者的相似度小于给定阈值,则该网格点的模拟结束,不需要继续比对其他数据样式,因此也在一定程度上提高了计算效率,但是存在阈值的给定具有一定主观性。HONARKHAH等[12]提出了一种基于距离的多点统计建模方法(DISPAT),该方法计算样式之间的相似度并建立距离矩阵,通过多维尺度分析进行降维处理,然后根据K均值聚类法来对样式进行聚类分析,DISPAT方法能够显著提高模拟效率,但其内存开销已远远超出普通计算机可承受的范围。针对上述问题,本文提出一种基于众数法聚类的多点地质统计学建模方法(CMMS),该方法能够显著提高模拟计算的效率,能够很好地再现训练图像中地质模式及统计特征,并且可以直接应用于连续性变量。
1 CMMS算法原理
基于样式的多点地质统计学建模方法核心思想是把训练图像(TI)中的地质模式提取并复制到模拟网格(SG)中,并且满足条件数据。在这个模拟过程中,一个关键的问题就是计算数据事件与数据样式的相似度。经典的基于样式的多点统计建模方法SIMPAT是采用的一次比对法,也就是计算数据事件与每一个数据样式之间的相似性。当数据样式较多时,计算量巨大。本文提出的CMMS方法其核心思想就是采用二次比对法,利用众数法对数据样式聚类,先比对数据事件与数据样式类的代表,找到数据事件所对应的数据样式类,然后再进行二次比对,找到最匹配的数据样式。通过这种方式大大提高模拟计算的效率,并且针对离散型变量和连续性变量采取不同的策略,取得了较好的效果。
1.1 相似度计算
在计算相似度之前,需要构建数据样式库,也就是全部数据样式的集合。定义ti(i,j)为训练图像上网格(i,j)处的值,pat(i,j)={ti{x,y}},x=[-n,n],y=[-n,n]为数据样式,样式大小为[2n+1,2n+1]。利用模板扫描训练图像,提取数据样式,并构建样式库。
针对离散型变量,数据样式与数据事件相似度采用如下公式计算:
式中:event[i,j]表示数据事件在位置(i,j)处的值,相似度用单个网格差异的累计和Distance表示。kij为网格(i,j)的权系数,如果在数据事件中该网格为非条件数据网格,则权值为1,如果是条件数据网格,则可以设置为较大的权值,例如5,这样在选取数据样式时会对条件数据优先考虑。Max函数的取值只能够是0或1,当网格(i,j)处的数据事件与数据样式一致时,则Max的值为0;反之,如果不一致时,则为1,也就是说不是具体相代码的差,而是代表相类型的差异。例如pat[i,j]为3,event[i,j]为1,它们的差Max函数返回的结果是1。
针对连续型变量,例如灰度图(灰度值0~255),可以采用如下公式计算:
Max(ti)与Min(ti)分别是训练图像中连续变量的最大值与最小值。当数据事件event[i,j]为空时,也就是说该网格点尚未模拟或非条件数据时,默认与数据样式一致,即pat[i,j]-event[i,j]=0。
1.2 样式聚类
SIMPAT方法在进行模拟前,需要先提取出训练图像中的数据样式。数据样式的多少与训练图像的大小、变量类型和扫描样本大小有关。例如三维二值训练图像(图1),使用13×13×9模板扫描后得到97 922个样式;二值训练图像采用9×9大小模板扫描后得到13 803个样式,采用15×15模板扫描后得到38 554个样式。对于三维多值训练图像样式数量可以高达数十万甚至百万级别。在模拟每个待模拟网格点时,都需要提取数据事件,并计算样式库中所有样式与数据事件的相似度来得到最相似的数据样式。样式库中存在很多相似但不完全相同的样式(图2),这些相似的数据样式在模拟时都可以很好地匹配数据事件。CMMS方法对数据样式先进行聚类,将相似的数据样式聚为一类。计算相似度时,不直接计算数据事件与数据样式的相似度,而是计算数据事件与数据样式类中的样式代表的相似度。先找到最相似的数据样式代表,然后在数据样式代表对应的这一类数据样式库中寻找最相似的数据样式。
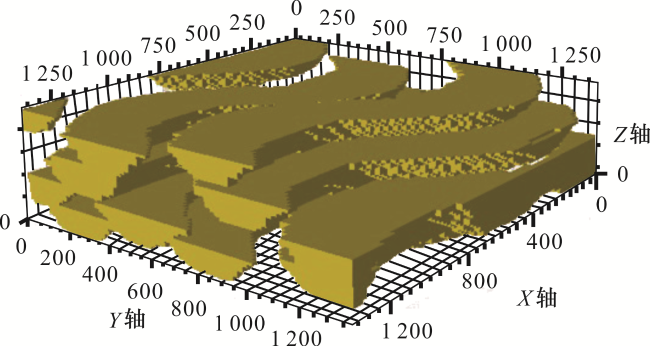
1.2.1 离散型样式聚类
1.2.2 连续性样式聚类
对于连续型变量的数据样式聚类不是采用众数法的方式,而是通过计算网格平均值的方式,如图2是计算红色方框内9个网格的平均值,将其作为聚类模板中一个网格的值。计算降维后的聚类样式之间的差异,采用逐点比较,如果降维后样式之间全部网格点的差异都小于给定阈值,则2个样式归为同一类。阈值越大,聚类能力越强,每一类包含的样式数量越多,降维样式库包含的类型越少,但是过大的阈值会使不相似的样式也聚为一类,导致模拟效果变差。
1.3 计算聚类后的样式代表
样式进行聚类后,先计算数据事件与降维样式库的相似度,每一个降维样式中包含一个或多个数据样式,需要一个可以与数据事件计算结果相似度的样式代表。对于离散型变量和连续型变量采用不同的策略,对于离散型变量,先对数据样式进行降维,然后在降维样式库中寻找对应的类就可以;对于连续型变量,首先计算聚类后数据样式的代表,直接采用取平均值的方法,降维后样式库某一类的样式代表就是该类中全部数据样式的平均值。
1.4 条件化策略
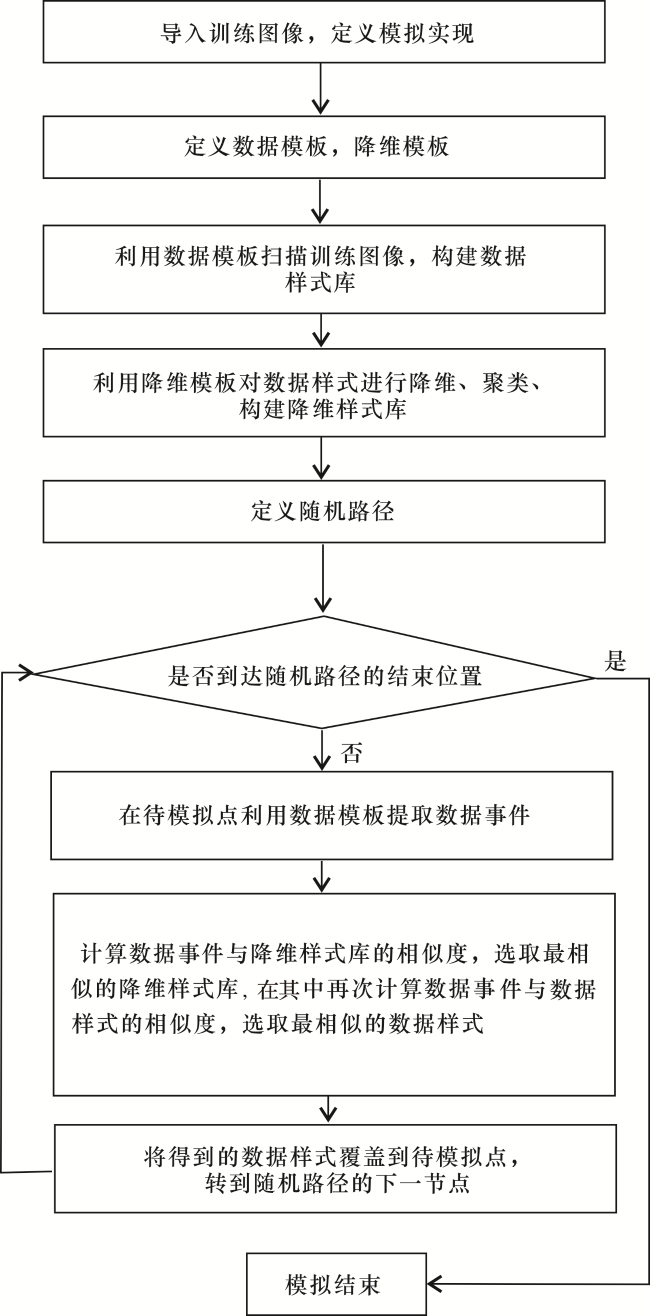
1.5 算法流程
2 CMMS算法测试
2.1 模拟效果测试
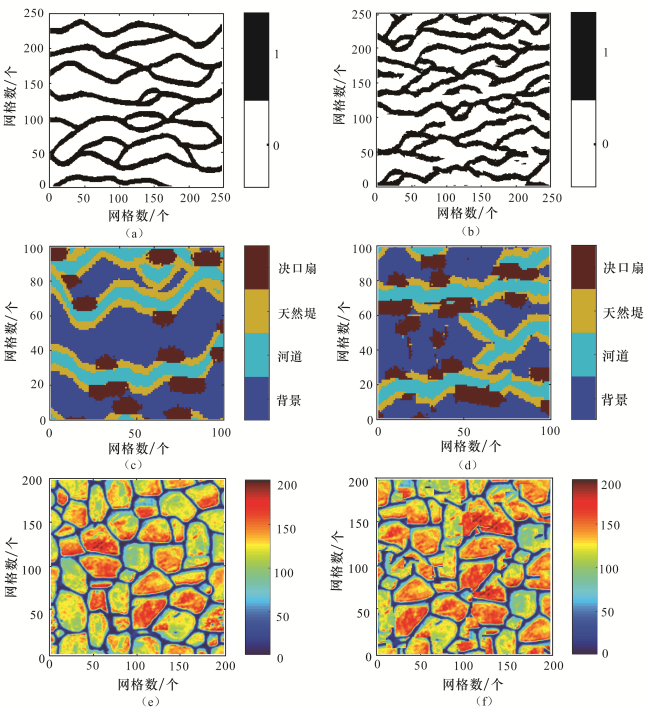
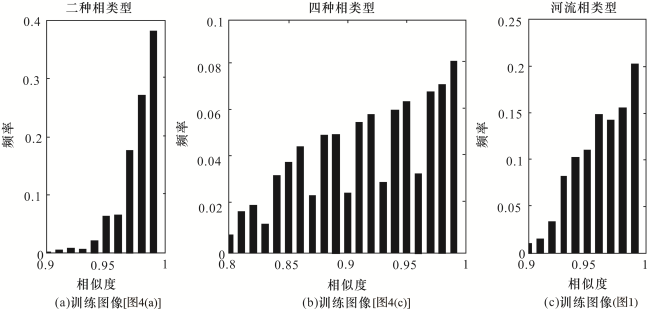
以3个二维训练图像[图4(a)[8]网格数量250×250、图4(c)Fluvsim算法的一个二维模拟实现,网格数量101×101、图4(e)[9]网格数量200×200]为例分别模拟3个实现[图4(b)—图4(f)]。二种相类型河道数据样式13 803个,聚为372类,模拟结果[图4(b)]再现了河道的形态及连通性。四种相类型数据样式6 513种,聚为261类,模拟结果[图4(d)]中河道、天然堤和决口扇的位置分布和训练图像中保持了较高的一致性。连续型变量采用设置阈值进行聚类,为了达到较好的效果需要多次尝试,本例中设置为5,模拟结果[图4(f)]中蓝色低值的孔隙能将岩石颗粒分开,并且岩石孔隙在平面上基本连通。通过这3个实例可以看出新设计的算法能够很好地捕获图像中的结构信息,并在模拟实现中较好地再现出来。
2.2 模拟时间对比测试
测试计算机的硬件配置如下:主频为3.7 GHz的英特尔i7-8700K处理器,16 GB内存。采用Visual Studio编译器及C#语言编写了SIMPAT和CMMS多点地质统计学算法,测试在相同开发环境下,CMMS算法与SIMPAT算法在相似度计算上的时间花费。分别对比了二维[图4(a)]和三维(图1)条件下模拟的计算时间。测试参数如下:二维训练图像网格数250×250,模拟实现网格数250×250,模板大小15×15,降维模板大小5×5,采用2重网格,多重网格的原理可以查阅文献[8]。三维训练图像网格数69×69×39,模拟实现网格数69×69×39,模板大小9×9×9,降维模板3×3×3,采用2重网格。测试结果如表1所示,采用二维训练图,SIMPAT相似度计算平均需要158 s,而CMMS算法只需要4~5 s,计算速度提高约30~40倍。采用三维训练图像,SIMPAT相似度计算平均需要1 535 s,CMMS算法平均需要44 s,计算速度提高约35倍。CMMS算法的聚类是建立在原有的样式库基础之上,并没有产生新样式,所以不需要很多额外的内存空间。测试表明CMMS算法和SIMPAT算法在内存上相差不大,均远小于普通PC电脑的内存总量。
表1 计算20个模拟实现平均耗时Table 1 Average consuming time of 20 simulation implementations |
| 训练图像 | 计算时间/s | |
|---|---|---|
| SIMPAT | CMMS | |
| 二维 | 158 | 4.3 |
| 三维 | 1 535 | 44 |
2.3 相似度计算
3 参数敏感性分析
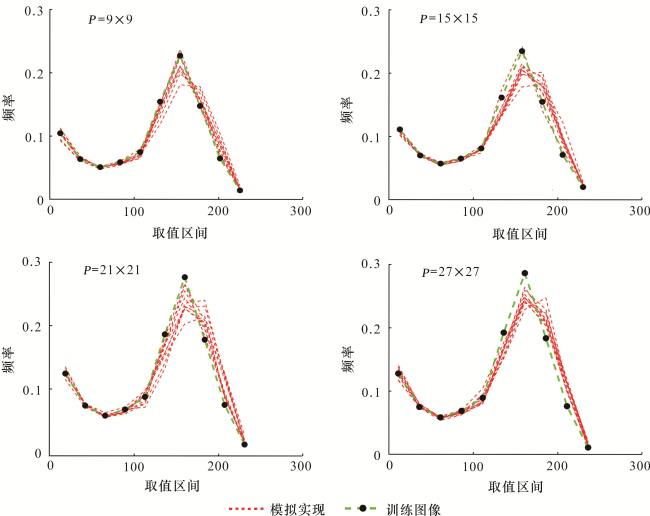
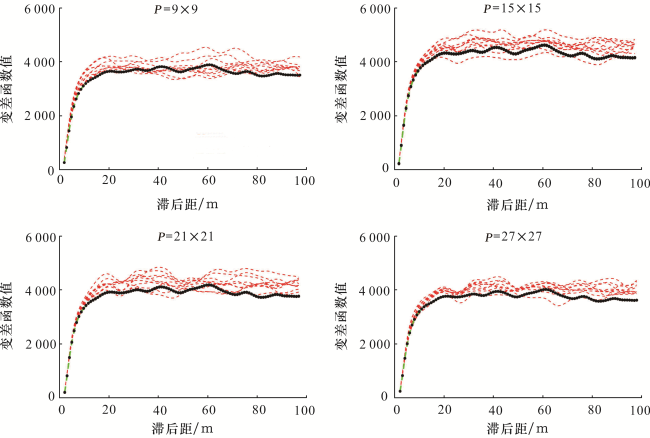
使用训练图像图4(a),对样式大小和多重网格参数进行参数敏感性分析。测试使用的模板为9×9、15×15、21×21、27×27,降维模板大小取1/9分别为3×3、5×5、7×7、9×9。表2为测试结果,研究表明:一重网格下随着样式增大河道百分比一直减少,河道形态特征逐渐接近训练图像。二重、三重网格下样式大小从P=9×9增加到P=15×15时河道百分比减少明显,河道形态变好,但是后续样式大小从P=15×15增加到P=27×27时,河道百分比及河道形态等特征变化不明显。以相邻河道距离为例,从训练图像图4(a)中可以看出,相邻河道之间的距离约为25~50网格。一重网格下9×9、15×15、21×21模板和二重、三重网格下9×9模板提取出的数据样式无法同时包含2条相邻河道,所以不足以刻画出训练图像中相邻河道距离这一特征,所以用这些模板模拟出的结果和训练图像相差较大。随着样式大小增大,或者增加多重网格重数,模拟结果中相邻河道之间的距离逐渐接近训练图像中相邻河道之间的距离,直到相等为止,并不会一直增大。因此可以得出结论:模板太小,提取出样式不足以反映训练图像中的河道结构及分布特征,模拟的结果失真严重;模板增大,数据样式足以捕获训练图像中的结构特征(河道宽度,相邻河道间距等),模拟结果越接近训练图像。当数据样式到已经能够完全包含训练图像的结构特征,到达最小合适样式,再增大数据样式对模拟结果影响不大。对比表中不同网格重数下P=15×15的3个模拟结果,使用相同的模板,三重网格模拟效果最优和训练图像比较接近。使用多重网格则可以扩大样式捕获结构信息的范围,避免定义过大的数据模板。
表2 参数敏感性测试Table 2 Sensitivity test of parameter |
| 网格重数 | 样式大小 |
|---|---|
 | |
4 统计特征
5 结论
多点地质统计学在储层建模领域应用越来越广泛,本文提出一种针对SIMPAT改进的多点统计建模方法CMMS,通过对原始数据样式根据降维模板进行分块统计,离散型变量取各分块的众数作为降维样式的值,连续性型变量取分块内的网格平均值作为降维样式的值,进而对原始样式进行降维、聚类分析,大大降低多点统计模拟中数据样式与数据事件相似度比对次数,显著提高了多点统计模拟效率,并且CMMS算法不会增加额外内存开销。通过多种测试分析对比,结果表明CMMS算法对地质模式再现程度表现良好,具有很好的应用前景。
 甘公网安备 62010202000678号
甘公网安备 62010202000678号
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}